Abstract
Video recognition models are typically trained on fixed taxonomies which are often too coarse, collapsing distinctions in object, manner or outcome under a single label. As tasks and definitions evolve, such models cannot accommodate emerging distinctions and collecting new annotations and retraining to accommodate such changes is costly. To address these challenges, we introduce category splitting, a new task where an existing classifier is edited to refine a coarse category into finer subcategories, while preserving accuracy elsewhere. We propose a zero-shot editing method that leverages the latent compositional structure of video classifiers to expose fine-grained distinctions without additional data. We further show that low-shot fine-tuning, while simple, is highly effective and benefits from our zero-shot initialization. Experiments on our new video benchmarks for category splitting demonstrate that our method substantially outperforms vision-language baselines, improving accuracy on the newly split categories without sacrificing performance on the rest.
Task and Benchmark
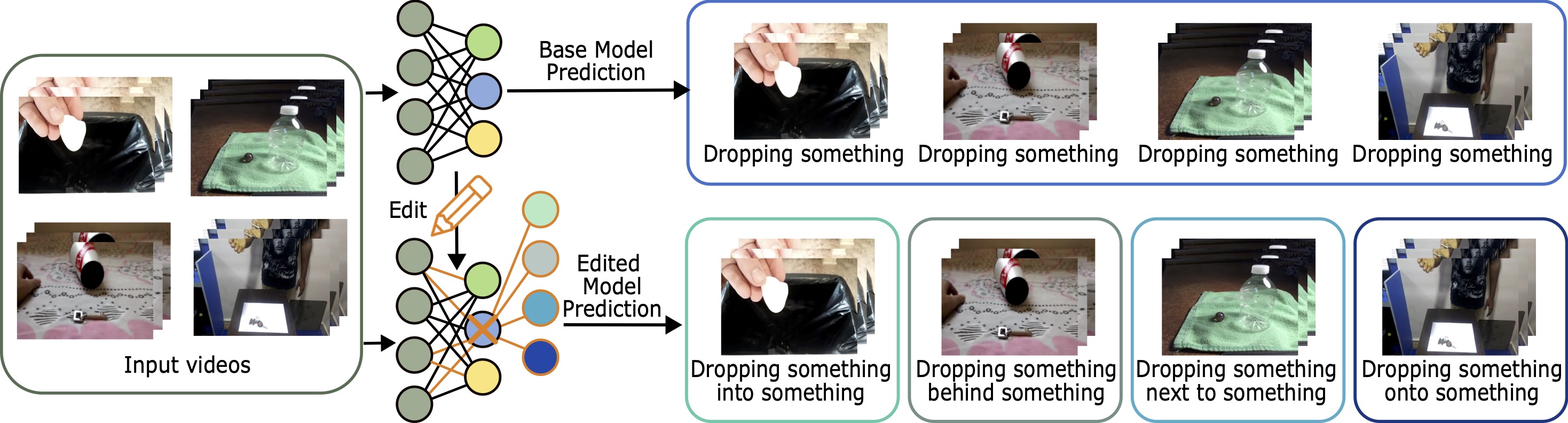
We address the problem of category splitting, as illustrated in the above figure, where a chosen coarse category in an existing classifier is refined into several fine-grained subcategories, while preserving performance on all other categories. This task setting introduces two key challenges:
Efficiency. Retraining the model for the new subcategories would require substantial data collection, annotation effort, and computation. We instead aim for a lightweight update that works with minimal additional data (low-shot or zero-shot) and computation.
Performance. The updated model should (1) exhibit generality, correctly recognizing unseen instances of the new subcategories, and (2) maintain locality, preserving predictions for all untouched categories.
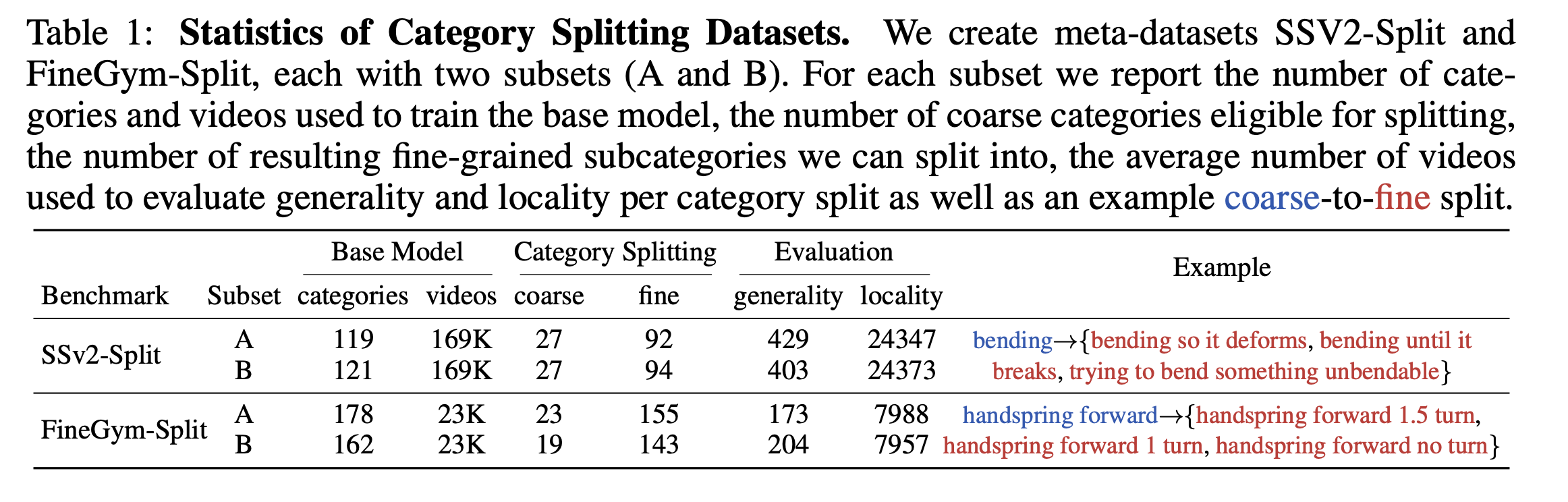
We construct two new benchmarks based on Something-Something V2 and FineGym288 by grouping fine-grained action categories into semantically coherent coarse categories. To simulate realistic annotation settings, we create two mixed-granularity splits for each dataset, where some categories are provided as coarse labels while others retain fine-grained annotations. These splits are used to train a base model, after which the coarse categories should be split into subtle fine-grained variants. Detailed statistics are summarized in the table above.
Zero-shot Category Splitting
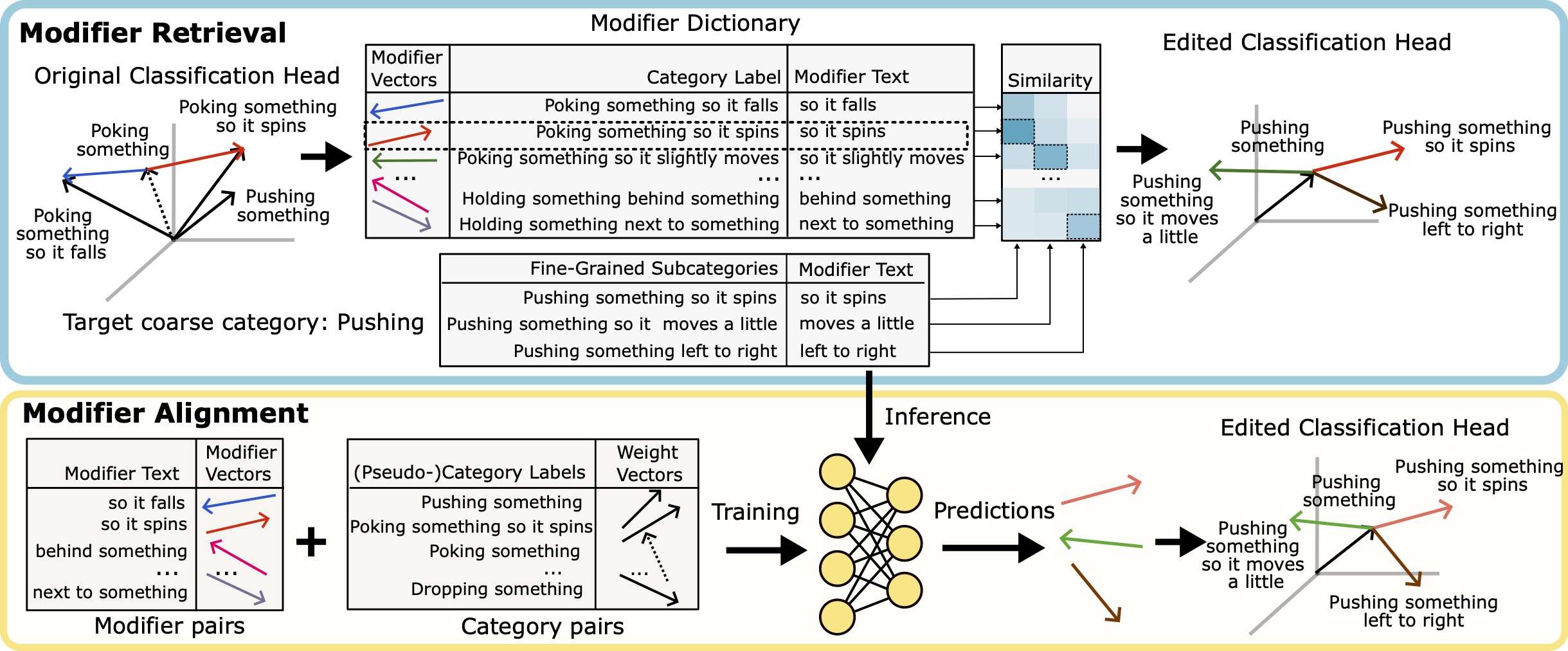
We propose a zero-shot category splitting method based on feature compositionality, where new subcategory weights of the classification head are created by combining a coarse category weight with an appropriate modifier feature vector that captures fine-grained variations. Modifier vectors are organized into a dictionary, with modifier text descriptions as keys and the corresponding vectors as values, allowing retrieval of appropriate modifiers for coarse categories. To generalize to unseen modifiers, we also introduce a lightweight alignment module that maps text embeddings of the description directly to modifier feature vectors.
Low-shot Category Splitting
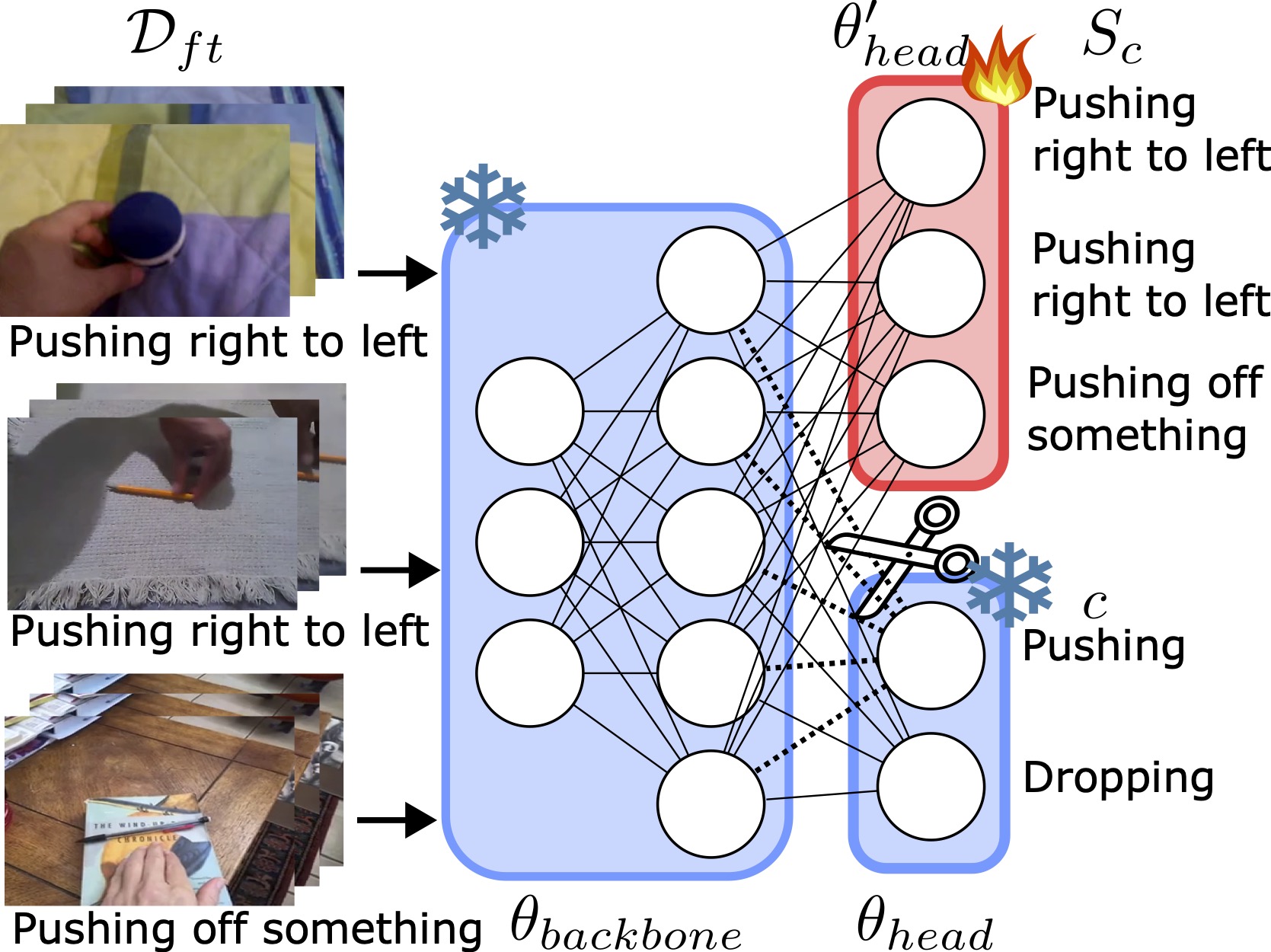
We also explore a naive low-shot approach, where the backbone and original classifier weights are frozen and only the new subcategory head weights are fine-tuned. Initializing the subcategory weights using the zero-shot method further improves performance.
Qualitative Results


We provide qualitative results on SSv2-Split, illustrating the capabilities and limitations of our method. The upper part of the figure shows that our modifier alignment can successfully further subdivide existing categories into fine-grained categories. The lower part highlights examples requiring genuinely new visual distinctions, which are more challenging since our edits operate only on the classification head and do not introduce new knowledge to the model itself. While certain concepts like "continues" or "deflected" may fail, our method also succeeds on previously unseen concepts such as "breaks" or "slanted surface."
BibTeX
@article{Liu2026Let,
title={Let's Split Up: Zero-Shot Classifier Edits for Fine-Grained Video Understanding},
author={Liu, Kaiting and Doughty, Hazel},
journal={International Conference on Learning Representations (ICLR)},
year={2026},
url={https://kaitingliu.github.io/Category-Splitting/}
}